Shadow System(以下SSと略することもあります)について解説している日本語記事が無かったので、自分が知っていることをまとめます。
シャドーシステムとは、トランプ記憶において2枚のカードを1つのイメージに置き換えて覚えるシステム(2card-system)の一つです。下の動画がかなり分かりやすいです。
Shadow System(Youtube)
2card-systemの歴史(?)
最初に開発された2card-systemはベンシステムと呼ばれるもので、これは単純に2枚のトランプに対して1つのイメージを割り当てることで2card-systemを実現してました。しかし、これには問題が在りました。52×51=2652個のイメージを用意する必要があり、それを作るのも練習するのも難しかったからです。
その後、シャドーシステムが誕生しました。シャドーシステムは、3桁のmajor system(0~999の数字に対応する1000個のイメージを作るシステム)を拡張して、従来の半分のイメージ数ある26×51=1326個のイメージを用意して2card-systemを実現しました。
トランプ記憶を2card-systemで記憶するとき52×51=2652個のイメージが必要なので、半分の1326個のイメージしか無い場合は、もう1326個の足りないイメージを補う必要があります。
シャドーシステムのそれぞれのイメージは2通りのペアを表していて、2枚のカードの内、1枚目のカードが赤か黒かによって区別してイメージを覚えるときに情報を加えてます。
1枚のイメージに1bit(2通り)の情報を加えることができれば、イメージは2倍の情報量を持つので、イメージが1326個しかなくても2652個のペアを網羅できるということですね。この区別の方法に場所移動や、シャドー(影)の概念を用いています。
場所移動
1枚目が黒か赤によって、イメージを同じ場所に置くか、次の場所に移動するかを選択することによって情報を加えています。この方法はtwo-block system(2ブロックシステム)と呼ばれていてJohannes Mallow, Alex Mullen, Lance Tschirhartなど、多くのトップ選手が1326枚のイメージとtwo-block systemを使用しています。
各カードのペアの内
1枚目のカードが「黒」なら「同じ場所に留まりイメージを重ねる」
1枚目のカードが「赤」なら「次の場所に移動する」
と情報を加えることで足りないイメージを補っています。
シャドー(影)の概念
シャドーの概念はこのtwo-block systemの「留まるか動くか」の代替案で、元のイメージとそれに対応する影のイメージのどちらを選択するかによって情報を加えています。なんだかかっこいいですね
各カードのペアの内
1枚目が黒なら「ケチャップ」
1枚目が赤なら「マヨネーズ」を場所に置くような方法です。
これは青木さんが解説してる動画を見ると分かりやすいと思います。
しかし、ほとんどシャドーの概念の方を使ってる人は居ません。ほぼ全員が2通りのイメージの区別に場所移動を採用してます。にも関わらず、多くのメモリーアスリート(Johannes Mallow, Alex Mullen, Lance Tschirhart・・・)が使っているような場所移動を用いるtwo-block systemが「シャドーシステム」と呼ばれているようです。
これには理由があり、シャドーシステムをポストした人は、0~999の3桁の数字システム(major system)で使われる1000個のイメージを、どのようにcardの1326個の変換に拡張して対応付けるかという画期的な提案したのですが、同じスレッドで区別の方法としてシャドーの概念を解説しました。現在2card-systemを使ってる人のほとんどがこの対応付けを採用してるほどまで影響が強いので、シャドーではなく場所移動を使ってるのにも関わらず、シャドーシステムという名前が浸透したのだと思います。(あと名前がかっこいい)
なので成り立ちの経緯から考えるとこれをシャドーシステムと呼ぶのは正確には誤用っぽいのですが、多くの人がこれをシャドーシステムと呼んでるので自分もそう呼びます。
Lance Tschirhart's "Shadow System"(シャドーシステムに関する命名問題にも言及されてます)
初心者が「シャドーシステムを使っているか」と聞いたところ「two-block systemを使ってます」と答えるくだりがあります。キューブ界にも様々な表記揺れがありますが、確かな用語の厳密さに拘るよりも、相手の意図を汲んで初心者に寄り添うような説明ができるとコミュニティ全体の利益に繋がると思いました。
本家shadow system
とにかくこういう経緯があり、シャドーシステムとは
①3桁の数字の1000個のイメージから、2枚のカードの組み合わせの1326個のイメージに拡張して対応付ける、その方法
②場所移動によって一枚目のスート(記号)が赤か黒かを区別する方法
というmethodだということが分かりました。
①カードと文字の対応付け(ナンバリング)
まず、3桁の数字のmajor systemでは
0~9の数字全てに子音を割り当てて、0~999の数字に対応する1000個のイメージを作成します
各数字は3文字の子音になるので、その子音の間に自由に母音を補って単語にします
例: 107→tsk→task
これを各カードの組み合わせに対応付けます
・一枚目、二枚目共に数字のペア
百の位:♤♤~♧♢の8通りのスートの組み合わせ
十の位:1枚目のカードの1~10の数字
一の位:2枚目のカードの1~10の数字
として割り当てます。この時点で800のペアに対して単語を対応付けられました。
・一枚目がJ/Qで二枚目が数字のペア
スートの組み合わせは8通りなので、使わない百の位の数字があります(400~499と800~899)
これをJ→8 Q→4のように割り当て、一枚目がJ/Qで二枚目が数字のペアは
百の位:1枚目のカードがJなら8、Qなら4とする
十の位:2枚目のカードの1~10の数字
一の位:♤♤~♧♢の8通りのスートの組み合わせ
また一枚目がJ/Qで二枚目がJ/Qのペアも同様に対応付けます。
これで新たに192のペアに対して単語を対応付けられたので、992/1352のイメージが作れたことになります。
残りのペアはmajor systemには無い単語なので追加子音と特殊ルールで単語を作成します。
・一枚目がKで二枚目が数字のペア
Kを新たな子音hを割り当てて
一枚目のK→h
二枚目の1~10の数字
♤♤~♧♢の8通りのスートの組み合わせ
できる文字列は3文字の子音になります
・一枚目が数字で二枚目がJ/Qのペア
先頭にsを付けます
♤♤~♧♢の8通りのスートの組み合わせ
1枚目のカードの1~10の数字
2枚目のカードがJなら8、Qなら4とする
できる文字列は4文字の子音になります。
・一枚目が数字で二枚目がKのペア
Kは無音になります
♤♤~♧♢の8通りのスートの組み合わせ
1枚目のカードの1~10の数字
2枚目のカードがK→(無音)
できる文字列は2文字の子音になります
・一枚目も二枚目も絵札のペア
今までと同じ要領で作ります
一枚目がKの場合は子音にhを用いて、二枚目がKの場合は無音になります
残りのイメージも作成できました。
このようなルールに基づいて作成された文字列からは(子音,子音,子音)のような単語が生成できます。
この変換は本家のリンクを見た方がよく分かると思います。
②場所移動の方法
一つのイメージに一枚目が黒のペアと一枚目が赤のペアの二通りが紐付けられるので、その区別を場所移動で行います。
1枚目が黒のペア→今の場所に留まり続けてイメージを置く
1枚目が赤のペア→次の場所に移動して新たにイメージを置く
これでshadow systemの解説は終わりです。
日本語で2cardsystemを使いたい
このシステムを日本語版に流用しようと思ったのですが、いくつか問題がありました。
SSではもちろん英語の音韻構造が使われています。
そこで、日本語の音韻構造を上手く利用した文字の割り当て方を考えました。
①子音だけでなく、母音も多く使う
英語と違い、日本語は子音だけでは発音できないので一つの子音は必ず一つの母音とセットになります。
なのでローマ字でひらがなを入力するときのように、子音→母音→子音→母音となる組み合わせが最も良いです。
最初に考えたのは
スートの組み合わせを子音
1枚目の数字を母音
2枚目の数字を子音
のように割り当てれば、必ず2枚のペアは子音+母音+子音の順番になるので、発音しやすくなると思いました。
しかし日本語の母音はアイウエオの5音と非常に少ないので、アー イー ウー エー オー ンなど母音を増やして使う必要があります。区別できる子音や母音を13個ずつ用意したり、それに合う単語を作るのは相当しんどいのでやめましたが、元々そのようなシステムを使ってる場合は拡張しやすいと思います。
次に、単純に母音と子音をごちゃごちゃにして割り振るという方法を考えました
a,i,u,e,o,k,s,t,n,h,m,r,yの13個の文字を数字に割り振ればいいと思ったのです。
しかしこれにも問題がありました。まず日本語は子音に例外なく母音がくっついて1モーラの発音になるので、子音が3つ連続した場合は3文字のひらがなの音になります。(tnk→田中のように)
この変換表を作るのがしんどかったのと、あとkasとksuのような似た文字列が両方「カス」になるので、その区別が難しいというのが一番キツかったです。これはローマ字でひらがなを表現するとき独特の問題だと思います。
②普通にひらがなをカードに割り当てる
いろいろ考えてる間に原点回帰したのですが、日本語のひらがなには五十音があり、濁点や半濁点を含めると52文字以上のひらがなが普通にあるので、これをそのまま使えばいいのではないかと思いました
これは1枚のカードを子音+母音の2文字で表すとも言えて、2枚のカードの組み合わせは子音+母音+子音+母音となります
英語の組み合わせでは子音+子音+子音の3文字になるので、音としては多くなりますが、文字数では得をすることになります。発音的にも2文字は「寿司」などスッキリしてるので、fsh→Fish, jmp→Jump, dsk→Deskのような単語と比べてもそこまで長い単語にはならない気がします
英語ナンバリングの方が良いという先入観があったので、何故これで上手くいくのか疑問に思ったのですが、これは文字数がデフォルトでも50以上ある日本語の優位性だと思いました。
結局これを採用することになりました。
完成版 2card 1image system
完成したスプレッドシートです。
詳細も載ってます。
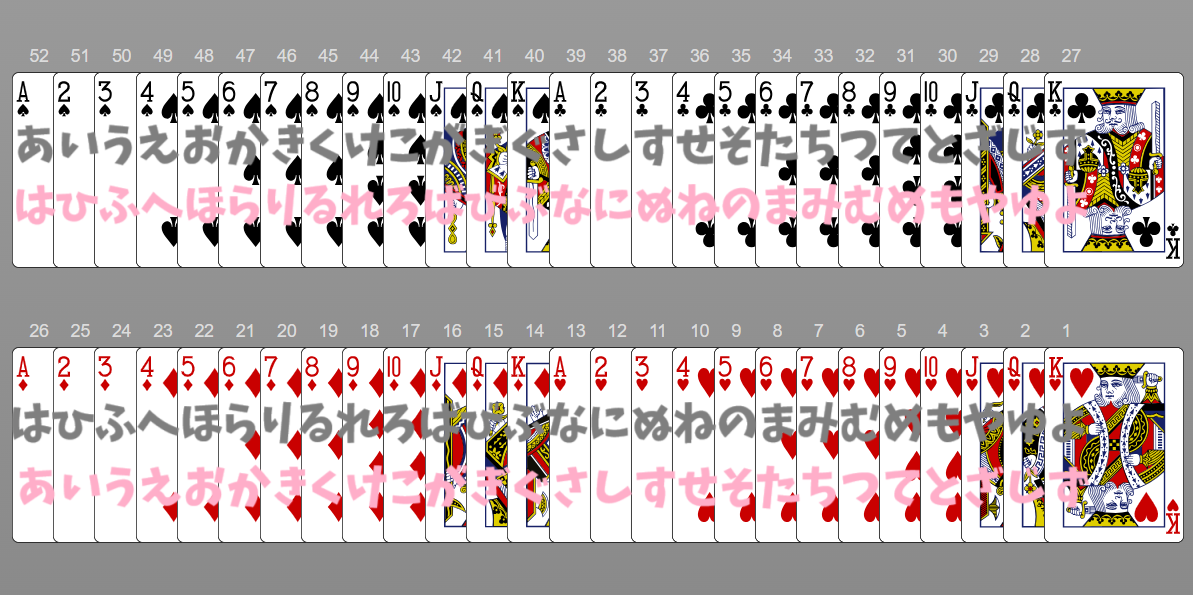
♤と♢また♧と♡を同一のカードの表裏と見なします。
1枚のカードにそれぞれ2文字のひらがなを振ります。
1枚目:黒でも赤でも表のナンバリングの「あ~ず」を使います
2枚目:1枚目が黒なら黒の文字を、1枚目が赤なら赤の文字を使います。同色なら「あ~ず」異色なら「は~よ」を使う具合です
例(左から右に読むとします)
同色の場合
くす

てと

同色の場合は(あ〜ず)のナンバリングを使います。例えば♢8♡3も同じくす玉ですし、♧9♧10も同じテントです。
異色の場合
こめ

あめ

一枚目の文字は(あ〜ず)のナンバリングを使いますが、二枚目の文字は(は〜よ)のナンバリングを使います
♢10♧9が同じ米で、♤A♡9が同じ雨です。
一つのイメージに一枚目が黒のペアと一枚目が赤のペアの二通りが紐付けられるので、その区別を場所移動で行います。
場所の使い方(ツーブロックシステム)
1枚目が黒のペア→今の場所に留まり続けてイメージを置く
1枚目が赤のペア→次の場所に移動して新たにイメージを置く
つまり場所に置くイメージの数は一定ではありません。延々と1枚目が赤のペアが続く場合は大量の場所を消費してしまいますし、延々と1枚目が黒のペアが続く場合は同じ場所に大量のイメージが置かれます。
前者は1in1みたいになるのでともかく、後者は困るので、黒が続く場合は4イメージごとに場所移動をして、赤だから場所移動した時と区別する為に場所の始めに煙のイメージを置くなど工夫をする方がいいです。
やってみて感想
トランプ記憶は画像記憶と同様に決められた中から回答するので、単語記憶などと違いイメージを厳密に区別する必要が無いので、レターペアの中にいくつも重複するようなイメージがあっても覚えたときの感じや消去法で推測できることが多いです。重要なのは全ての組み合わせをちゃんとイメージすることだと思いました
やはり2652イメージよりも実用性が高い気がします。これは出てくる組み合わせの数が小さい方が何度も出てくるのでイメージの練度が上がるからです
レターペアを埋めるのにhinemosと国語辞典を利用しました
特にhinemosのサジェストでは有用な候補がたくさん出たので、とても感謝しています。
ネットミーム、ポケモン、ドラクエ、アニメキャラの名前・・・なんでも使いました。
このシステムに至るまでの経緯
自分は最初に1card1image systemの2in1でトランプ記憶をやってました。
記録としては1分を切れそうで切れないくらいで、大会では2分を切ったのが最短でした。
もともと目隠しルービックキューブで24個のステッカーにひらがなを割り当てて、20文字(10単語)くらいを記憶していたので、52枚のトランプが52個の単語になって26個も場所を消費するのは、なんだか違和感ががありました。
52枚程度だと短期記憶の領域に残りやすいので、システムや場所を鍛えまくれば1in1やPAOで良いタイムを出せるので、複雑な2card-systemを作るよりもその時間で2in1の練習をした方がタイムが速くなるとは分かってたのですが、ペアで記憶した方が覚える単語も減るのでやりやすくなるかなと思ったのがきっかけです。
そこで、52枚のトランプに52文字のひらがなを割り振り、2枚の全ての組み合わせにイメージを作るというレターペアシステムを考えました。目隠しルービックキューブの練習から、レターペアを組み合わせて即興でストーリーを作る力と文字をダイレクトにレターペアに変換していく力には自信があったので、このシステムは使いやすいと思いました。
早速ナンバリングに慣れさせるためにBSAのアプリで練習しました。文字として読み上げるだけなら25秒くらいになってからトランプ記憶の練習を始めました。
レターペアは埋まらないものの、全てのカードが1文字になったので、不完全な2card 1image systemとして完成しました
このシステムでSCCでは76秒のタイムを出すことができました!このとき世界大会まで勝ち上がったyasさんや外園さやかさんと話したのを覚えてます
しかし、52×51のレターペア表というのはやはり現実的でなく、正直埋められた単語は半分ほどでした。分からない2文字は逆から覚えて場所に置くとき逆さまにしたり、1文字ずつイメージにして組み合わせたりしていたのですが、それだとカードにひらがなを振るメリットが半減してしまうので、悩んでました。
そこでshadow systemというものを知り、日本語に適応できないかといろいろ考えた結果が今回紹介したシステムです。しかし、筆者はまだこのシステムでは1分しか切れてません。またトランプ記憶の大会があれば練習したいと思います。
何か変換や記憶方法で一つでも学びがあれば幸いです。
参考
Alex選手のコメント
リンク一覧
発音のルール
シャドーシステムのシート